PPO对于离散、连续动作空间
PPO对于离散动作空间的学习效果较好
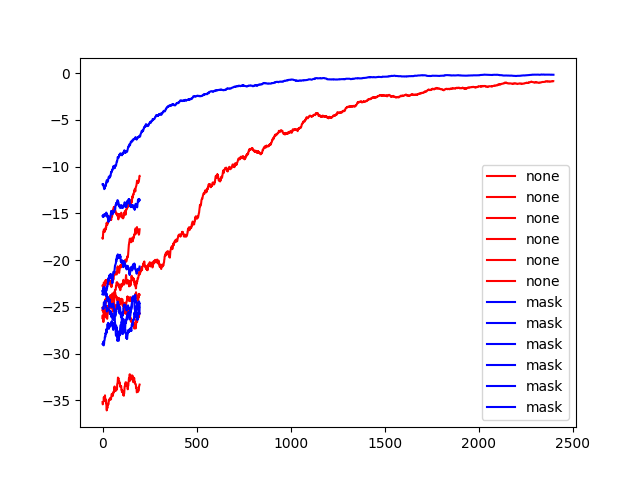
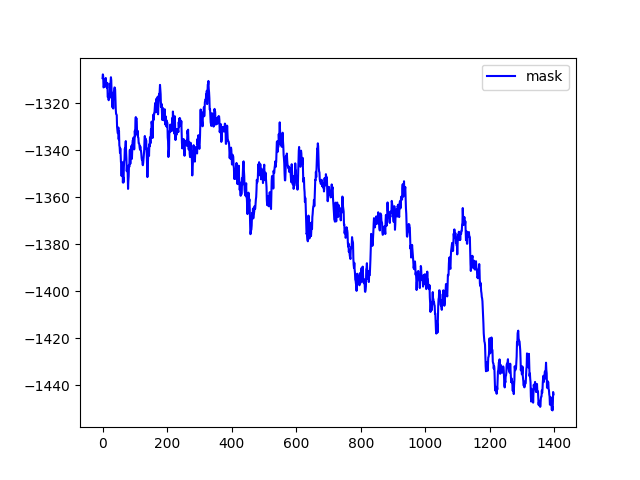
对于连续动作空间(Pendulum-v0),当仅训练 value loss 时,奖励不上升反而下降。
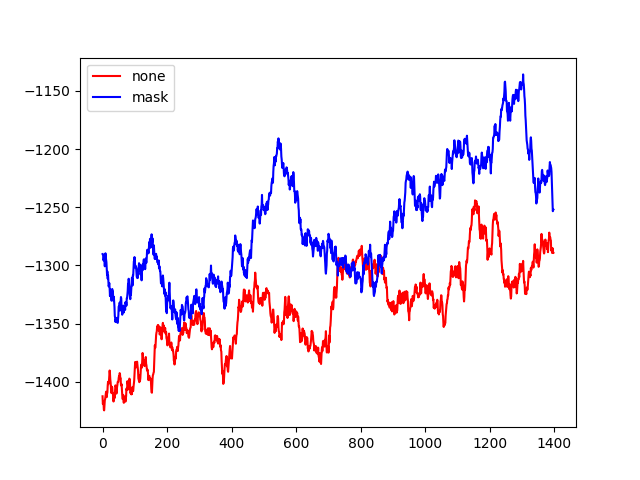
因此,将 value network 和 policy network 分开,得到得分(100个回合的均值)随训练回合的变化
深度学习推荐
深度学习推荐
深度学习推荐
深度学习推荐
深度学习推荐
深度学习推荐
深度学习推荐
机器人推荐
文贝推荐
深度学习推荐
墨之科技,版权所有 © Copyright 2017-2027
湘ICP备14012786号 邮箱:ai@inksci.com