将一次决策过程中得到的数据表示成下图。policy 获取 obs 并生成 action,施加 action 于 env,得到是否结束标识 done,即时奖励 reward,以及新状态的 value。
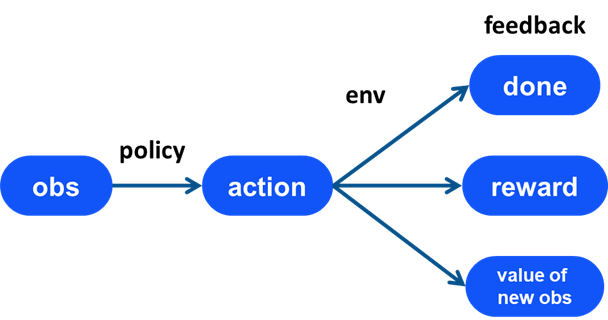
在 DeepFire 程序中,需要注意:
- 得到当前的 obs 和 action
- 得到的 reward 和 done 是上一个 action (上一次决策)产生的
- value of new obs 需要下次决策中观察 obs 才能得到
程序设计
为了使程序设计变得简单,将每一次决策中的 obs, action, reward, done, value of obs 保存成列表。当列表长度比 GAE horizon 多 1 时,计算 advantages 并保存数据供网络训练。提取数据的方式如下表。
实际是先处理,再保存的过程。
|
|
t+1 |
|
|
obs |
|
|
|
action |
|
|
|
reward |
|
|
|
done |
|
|
|
value of obs |
obs |
new obs |
墨之科技,版权所有 © Copyright 2017-2027
湘ICP备14012786号 邮箱:ai@inksci.com