ppo_parameterized-bins
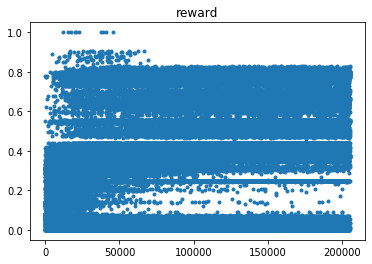
同一个算法,进行了 5 次实验,两次成功收敛,三次没有收敛到最优(reward = 1.0),如图:


===========================================================


========================================================
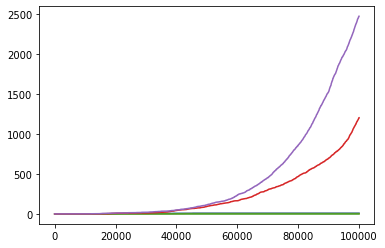
注意到成功收敛的两张奖励图,在时间前期,奖励的值就偏好。因此,按时间线对大于 0.99/0.83 的奖励个数进行计数。如图:
> 0.99
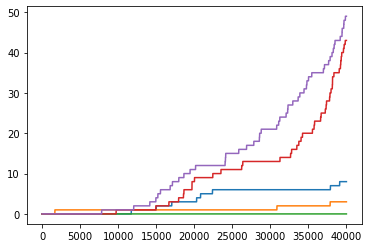
> 0.83
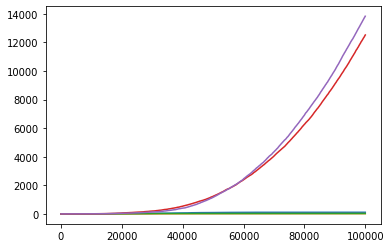
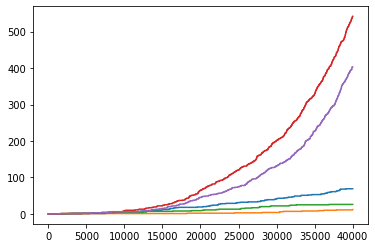
可见,能够收敛到最优的实验,在前期获得高奖励的次数就偏多。
深度学习推荐
深度学习推荐
深度学习推荐
深度学习推荐
深度学习推荐
深度学习推荐
深度学习推荐
机器人推荐
文贝推荐
深度学习推荐
墨之科技,版权所有 © Copyright 2017-2027
湘ICP备14012786号 邮箱:ai@inksci.com