PPO 中的 policy gradient loss 变化规则
一、如果不对 policy networks 训练,即 loss 中只有 value loss 项,则 policy gradient loss 始终为 0
因为动作的新旧概率总是一样,比值为 1。所有 Adv 的求和为 0,因为 Adv 已进行了归一化。
二、在训练后期,policy gradient loss 应该收敛到 0。因为后期策略收敛,对动作的输出分布基本不变。
不对 policy networks 训练,policy gradient loss 就为 0。这和深度学习中其它的 loss 不一样。
baselines 例子分析
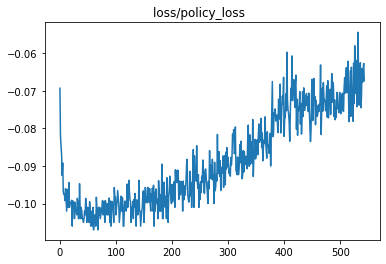
policy gradient loss 应该是由 0 下降,然后回到 0。
图的前期有一个骤降。后期没有收敛成熟,所以未到 0,但趋势是回到 0。
深度学习推荐
深度学习推荐
深度学习推荐
深度学习推荐
深度学习推荐
深度学习推荐
深度学习推荐
机器人推荐
文贝推荐
深度学习推荐
墨之科技,版权所有 © Copyright 2017-2027
湘ICP备14012786号 邮箱:ai@inksci.com