信任域策略优化算法 trust region policy optimization
概率比
TRPO 算法的优化目标函数为:
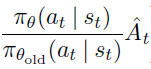
其中,At 为动作优势值,前一项为动作在当前和上一步策略中的概率比(likelihood ratio),概率比公式的代码为:
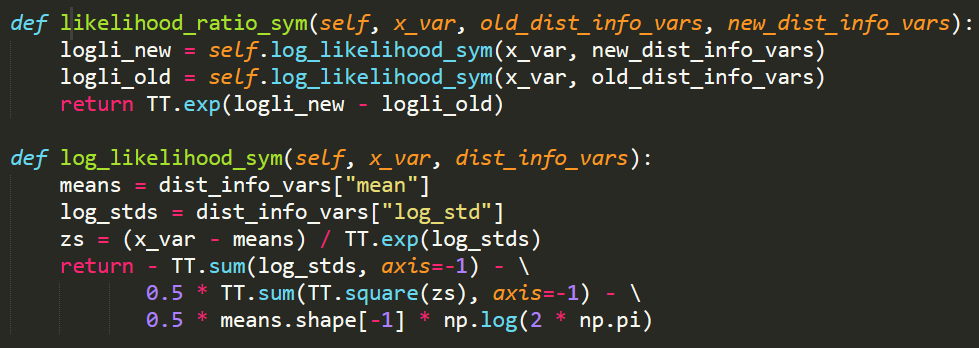
可见,这里使用了 log 函数,相减对应于公式中的相除。
注意这个公式和 vanilla policy gradient 不一样。这(可能)和重要性采样 I ... ...
评论:
-
[#{{item.num}}] {{item.post.nickname}}
{{item.post.textarea}}
墨之科技,版权所有 © Copyright 2017-2027
湘ICP备14012786号 邮箱:ai@inksci.com

