IMPALA 用来一次性训练一个智能体以应对于多任务(training a single agent on many tasks at once)。
其与 A3C 在分布式训练中一个重要的区别如下:
A3C: communicate gradients.
IMPALA: communicate trajectories of experience.
这篇论文中提出了一个算法:
V-trace: a novel off-policy correction method.
为什么 IMPALA 中要使用 V-trace 这样一种为 off-policy 设计的算法呢?原因:

关于这个现象,可以用一个词描述:
policy-lag
-----------------------------------------------------------------
文章阐述的两个概念:
1、增强学习的目标不是使当前的奖励 $ r_t $ 最大,而是使未来奖励折扣和的期望 $ V(x) $ 最大。

2、特别地,对于 off-policy RL 算法,需要干的一件事就是使用一个策略(behaviour policy)得到的采样数据来计算另一个策略(target policy)的 $ V(x) $。

--------------------------------------------------
而 $ V(x) $ 的值究竟为多少?前面说过,可以使用采样数据来近似计算。使用 n 步数据进行计算,$ V(x) $ 的近似值为 $ v_s $。
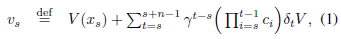
其中,
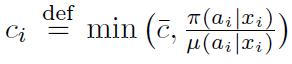
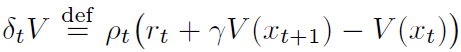
... ...
-
[#{{item.num}}] {{item.post.nickname}}
{{item.post.textarea}}
墨之科技,版权所有 © Copyright 2017-2027
湘ICP备14012786号 邮箱:ai@inksci.com

