论文:Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
首先,看论文的算法部分:

红色框标记部分,为算法(智能体)和环境交互并采集数据的过程:
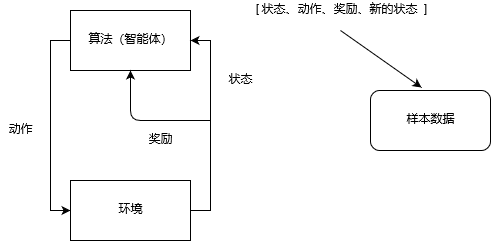
后面的梯度更新部分,共更新了3个网络的参数:值函数网络、Q函数网络和策略网络。
Q 函数网络
在上面算法中,对 Q 的参数更新时,i 可取值 1 和 2(橙色下划线),这是因为使用了两个 Q 函数网络。
Soft Actor-Critic 这篇论文中的解释:

翻译(仅供参考):
我们的算法同样在策略更新步骤中使用了两个 Q 函数来消除 正向偏差,众所周知,这样会降低基于值方法的性能(但是更稳定,译者补充)。特别的,我们使用两个 Q 函数网络的参数,独立地更新它们来优化函数 JQ,在进行值梯度和策略覆梯度计算时,使用这两个 Q 值的最小值。
Soft Actor-Critic 论文中的 Q 函数公式,Q 学习算法中的贝尔曼迭代公式:
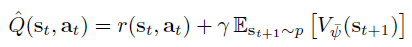
目标网络的参数更新
最后一个公式(蓝色下划线),是对“目标值函数网络”(target value network)的更新。使用“目标网络”(target network)是deepmind 提出的实现稳定的方法。较早的论文可以参考:Human-level control through deep reinforcement learning。
Soft Actor-Critic 这篇论文中的解释:
... ...
-
[#{{item.num}}] {{item.post.nickname}}
{{item.post.textarea}}
墨之科技,版权所有 © Copyright 2017-2027
湘ICP备14012786号 邮箱:ai@inksci.com

