值分布增强学习算法 分布式贝尔曼算子 a distributional perspective on reinforcement learning
论文:a distributional perspective on reinforcement learning
http://inksci.com/w/pan/A%20Distributional%20Perspectiveon%20Reinforcement%20Learning.pdf
第二部分:
贝尔曼算子(Bellman operator)
第三部分(我没有看):
分布式贝尔曼算子(Distributional Bellman operator)
第四部分:
基于分布式贝尔曼最优性算子的算法
如下图,横坐标为离散的值 V,V 的取值范围从 Vmin 到 Vmax,被均等离散成 N 个。纵坐标是这个值对应的概率。
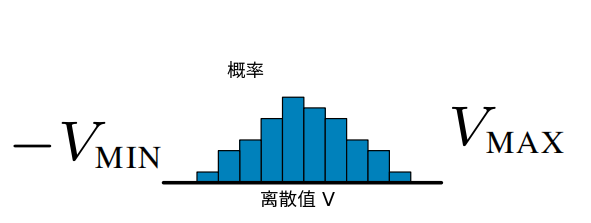
论文中:
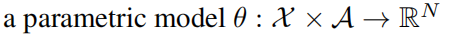
一个参数模型 $ \theta $。RN 表示一个 N 维的实数向量,易知 RN 和上面的离散值概率分布图是等价的。于是可知,神经网络的参数是 $ \theta $,输入为状态和动作,输出为 N 维的实数向量,即离散值概率分布。
算法
... ...
评论:
-
[#{{item.num}}] {{item.post.nickname}}
{{item.post.textarea}}
墨之科技,版权所有 © Copyright 2017-2027
湘ICP备14012786号 邮箱:ai@inksci.com

